Suit: Building a Verifier for Law
Law looks like text, but it does not behave like text. RAG systems cannot traverse genealogies or transfer histories. And their guesswork cannot be verified.
Suit: Building a Verifier for Law
Law looks like text, but it does not behave like text. RAG systems cannot traverse genealogies or transfer histories. And their guesswork cannot be verified.
Hemanth Bharatha Chakravarthy · 2026-04-08 · jhana.ai/blog/suit-verification
Suit ticks the simple boxes:
- MIME-agnostic, multi-modal—so PDFs but also handwriting, sitemaps, patent drawings & photographs
- Arbitrarily large contexts, routinely does 10,000+ pages in production
But our challenge was building a version of verification, à la Lean or other math formalization devices. The problem statement is that LLMs make proof generation cheap, but verification expensive. So, if we can constrain LLMs with notation to formalize inductive building blocks, we can verify the proof candidates generated by LLMs easily.
Suit does something similar. As a result, the user gets briefs or tabulations that are verified against the entire document space, with pinpoint footnotes that jump to paragraph/page. The user is able to study the files via AI indexing (spatial), via knowledge graph (thematic), or via query (ad hoc).
RAG systems rely on AI agents searching key terms iteratively. A result might slip through because of phrasing differences. Some scanning damage is ignored. And structured forms like genealogy trees or transfer histories are presented as low-resolution text. RAG offers no guarantees.
Suit doesn't wait till the point of inference—when a prompt is raised—to start mapping available documents. It has a complete map at the point of inference.
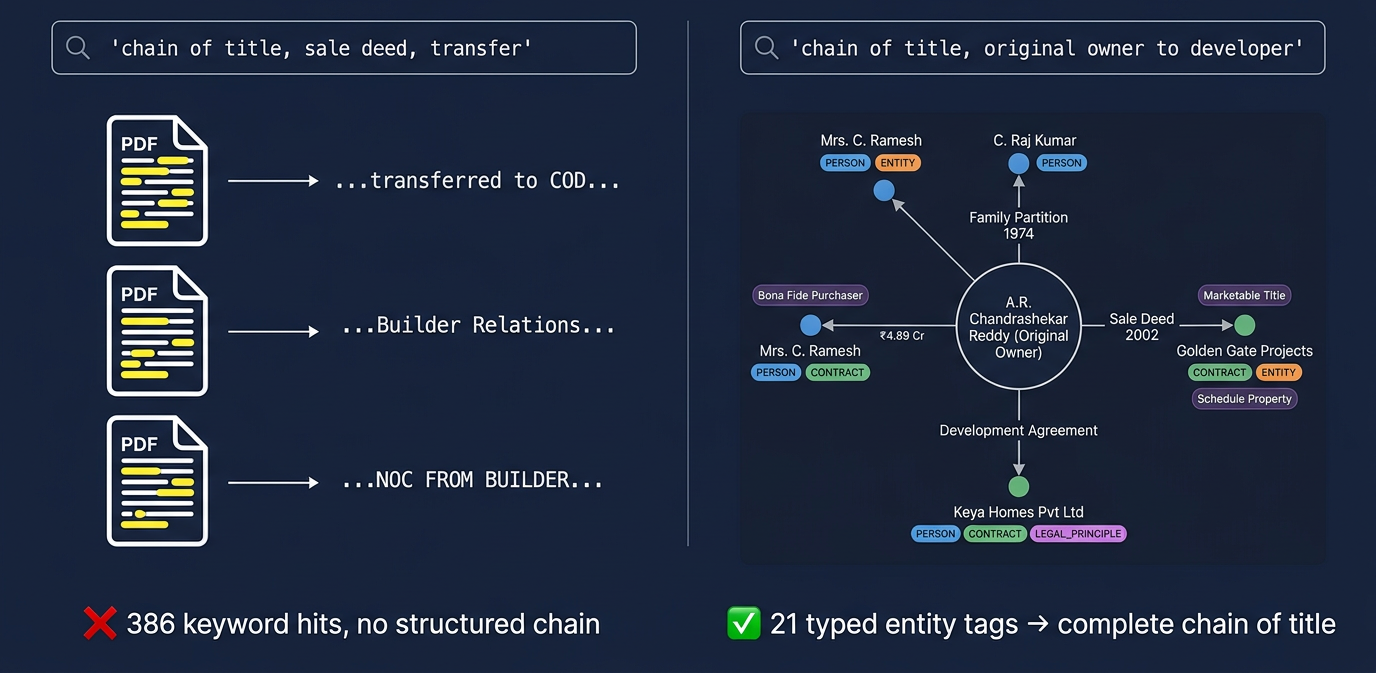
Suit embeds candidate tags → finds actual parties with roles (A.R. Chandrashekar Reddy as Original Owner, Golden Gate Projects as Purchaser, Keya Homes as Developer) → jumps across legal principles (Chain of Title Consistency, Bona Fide Purchaser) and specific instruments (Sale Deed 17.05.1972, Conveyance Deed). Traversing edges traces the complete provenance: Family Partition 1974, registered partition 1978 (Doc 2910/78-79), khata transfer to C. Ramesh and C. Raj Kumar, and the ₹4.89 Cr sale to Golden Gate under Chapter XX-C of the Income Tax Act.
So, we can connect two legal claims from distinct briefs that rely on the same precedent:
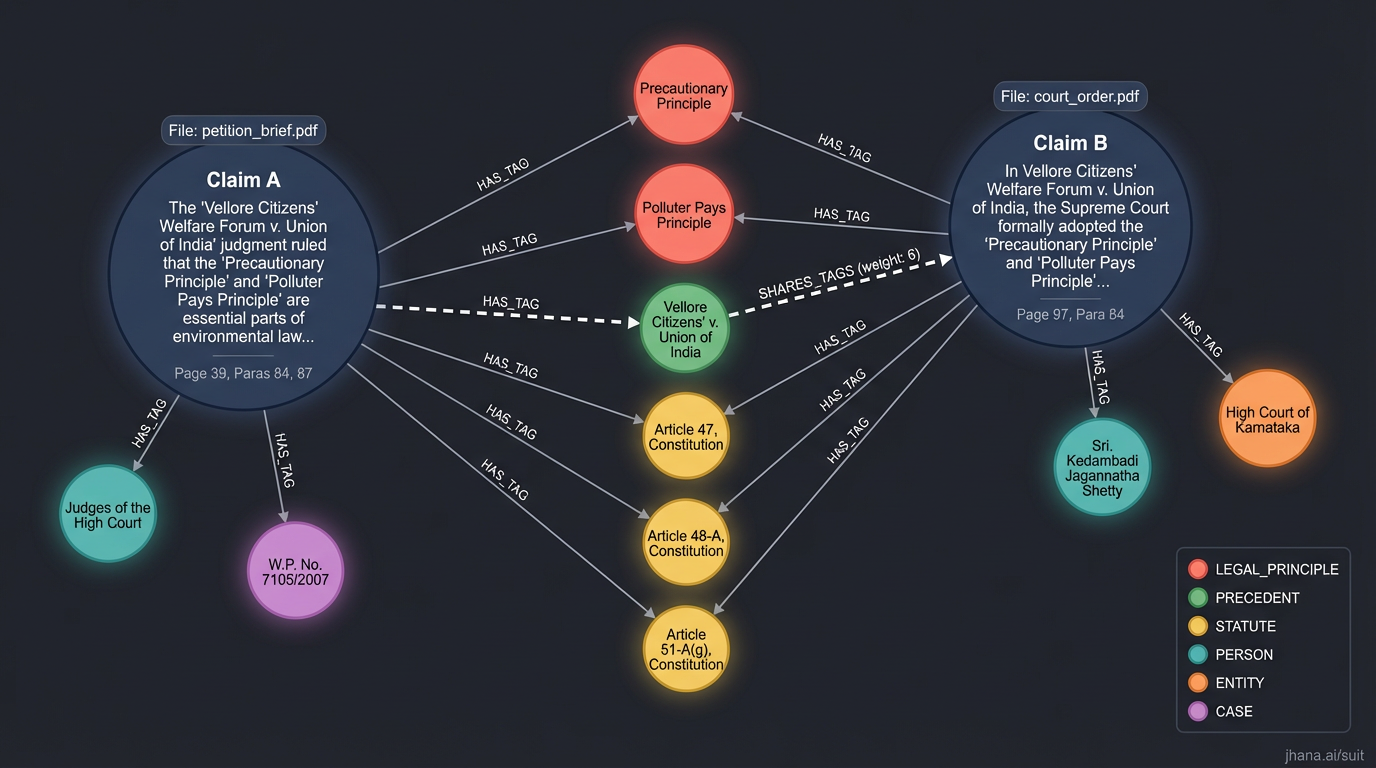
Or we can jump across files in a large bundle, through structural connections. These roles, relationships, and issues are computed in reverse from the entire document set. “Backpropagated,” so to speak. So, there are stable roles and relationships. And there are deterministic ways to measure and identify them.
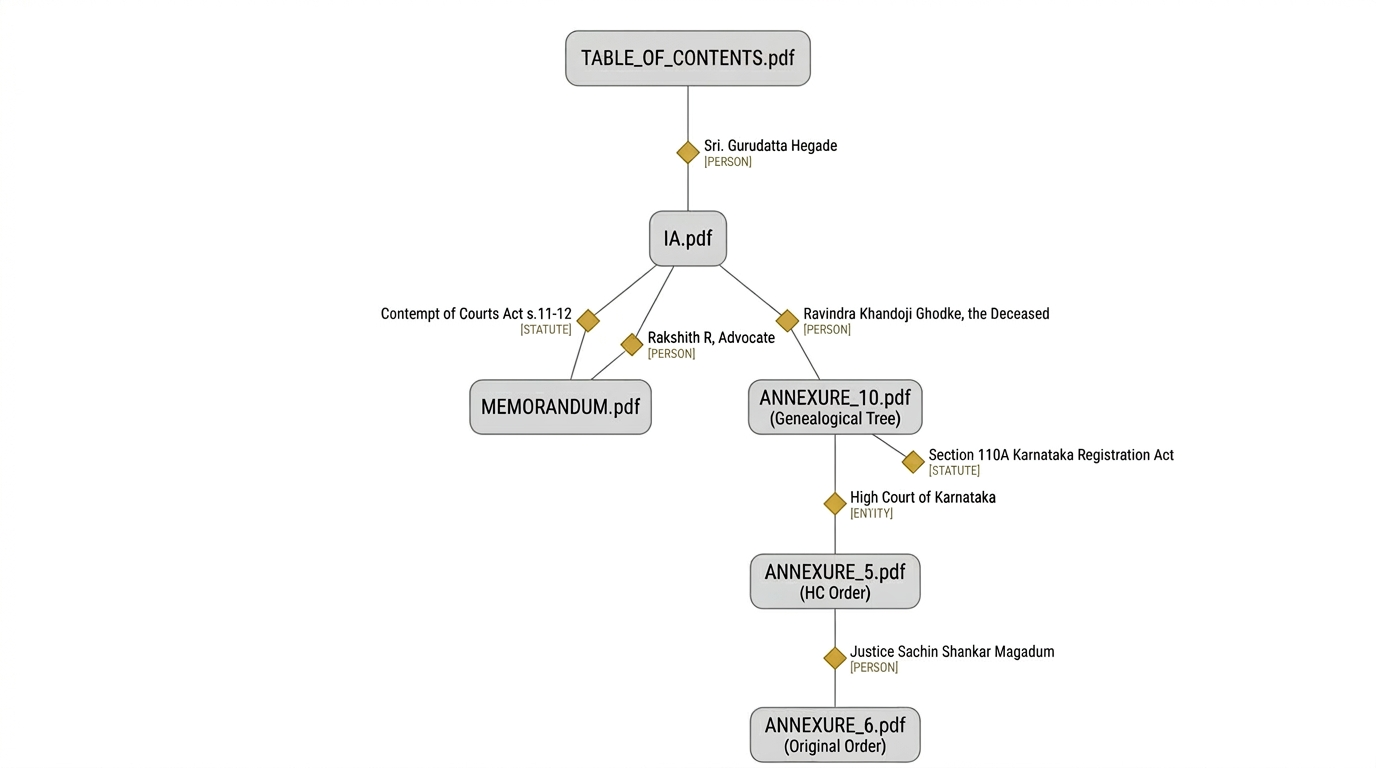
Our proprietary SOTA work here is on:
- (A) the representation or state model for legal that allows agents to "traverse" by role, precedent, or other reference,
- (B) a bijective embedding between raw files (token space) and the state graph,
- (C) a quasi-formal verification system that encodes and resolves legal rules or logics.
Motivating situations
- Creating operative headnotes for judgments to send to prisons, tax authorities etc → MUST differentiate between judge quoting lawyer and judge's own opinion → DETECT role and relation
- Emergent logic/contradictions e.g., can&rquot;t have 2 exclusive contracts with different vendors → ENFORCE rule
- Identifying scanning damage in portion of lawyer's brief → DETERMINISTIC sourcing, not probabilistic RAG
| Palantir | Lean | Suit | |
|---|---|---|---|
| Core claim | Structure > raw data | Proof > assertion | Legal objects > documents |
| Substrate | Ontology (digital twin) | Type theory (formal logic) | Legal state graph & types |
| Verification | Governance + actions | Kernel type-checking | LLM-as-a-judge rule enforcement |
| AI pattern | AIP operates over Ontology | LLM generates, Lean verifies | Generate candidates, verify against legal constraints, select |
| Trust model | "Don't touch raw data" | "Don't trust unproven claims" | "Don't trust unverified legal work" |
Benchmark
In 2025, we ran a tournament-style benchmark à la LMSYS Chatbot Arena — blinded, randomized, with 38 NLS-trained legal evaluators scoring headnotes from jhana, SCC (the human gold-standard for Indian law, 50+ years), and GPT-4o (then SOTA) across 12 Supreme Court judgments.
Headnotes Arena — Bradley-Terry Leaderboard
Elo Rating
1173
#1 overall
vs. GPT-4o
73.1%
BT win prob (p < 0.001)
vs. SCC
58.2%
BT win prob (human SOTA)
Pairwise Win Probabilities (Bradley-Terry MLE)
| vs. jhana | vs. SCC | vs. GPT-4o | |
|---|---|---|---|
| jhana | — | 58.2% | 73.1% |
| SCC | 41.8% | — | 66.1% |
| GPT-4o | 26.9% | 33.9% | — |
vs. Human SOTA (SCC) — Paired t-tests, n = 115
Readability
+0.47
p = 0.002 **
Enjoyability
+0.68
p < 0.001 ***
Accuracy
n.s.
Comprehensiveness
n.s.
jhana leads on readability (+0.47, p = 0.002) and enjoyability (+0.68, p < 0.001) with no statistically significant difference in accuracy versus the human editor. Two independent evaluation methods — cardinal Likert scoring and ordinal three-way voting — produce the identical leaderboard. Our repeated experience has been that our AI is clearer, but also more likely to surface costs and commercial risks directly. It is structurally free of the principal-agent misalignment endemic to billable-hour practice. And it is often far more powerful than overburdened law clerks who must study 1000s of pages every day.
Suit now powers 5+ courts in production. These benchmark results predate the current system — the pipeline evaluated in that study, KURAL, is Suit's direct predecessor. Current production performance is radically higher, as frontier models have correspondingly improved. RAG over legal documents hallucinates at the point of inference. You let LLMs run searches and hope for the best. This is not suitable for high-stakes situations that are evaluated tabula rasa, like a courtroom or a forensic audit.
See also: Suit: The Ontological Layer for Law — our lawyer-facing technical blog on Suit.
Discussion