Paralegal: a model-agnostic matter runtime, not a legal chatbot
Research the law, keep every source, survive long matters, and turn the answer into an editable DOCX.
Paralegal: a model-agnostic matter runtime, not a legal chatbot
Research the law, keep every source, survive long matters, and turn the answer into an editable DOCX.
Hemanth Bharatha Chakravarthy · 2026-04-26 · jhana.ai/blog/paralegal-agent
jhana Paralegal is a model-agnostic legal execution stack for research, drafting, and long-running matter work. A messy instruction can become a planned legal run: task triage, HyDE, structured search across judgments, statutes, and books, web investigation with page fetches and document OCR, persistent bibliographies, long-context session memory, and a handoff into a DOCX-native drafting engine with redlines, citations, XML-level document control, rendered previews, revert, diffs, and version control.
The execution stack
The product is not one prompt wrapped around a search index. It is a router, a research agent, a bibliography layer, a session runtime, and a document-operating drafting system. Each layer is useful alone; together they make legal work feel less like chatting with a model and more like running a matter through a small, persistent legal team.
A bag of other tricks create token efficiencies in how tool outputs are read and understood by agents. The user-visible result is broader search, deeper reading, fewer repeated prompts, and less context lost to plumbing.
1. Legal task router, clarifications, and plan
The first step is not to answer. The system plans task depth, inference budget, attached-file relevance, draft state, and whether the work should proceed as research, clarification, drafting, or a handoff between agents. If the instruction is underspecified, it can pause for clarification rather than spend a large model run guessing.
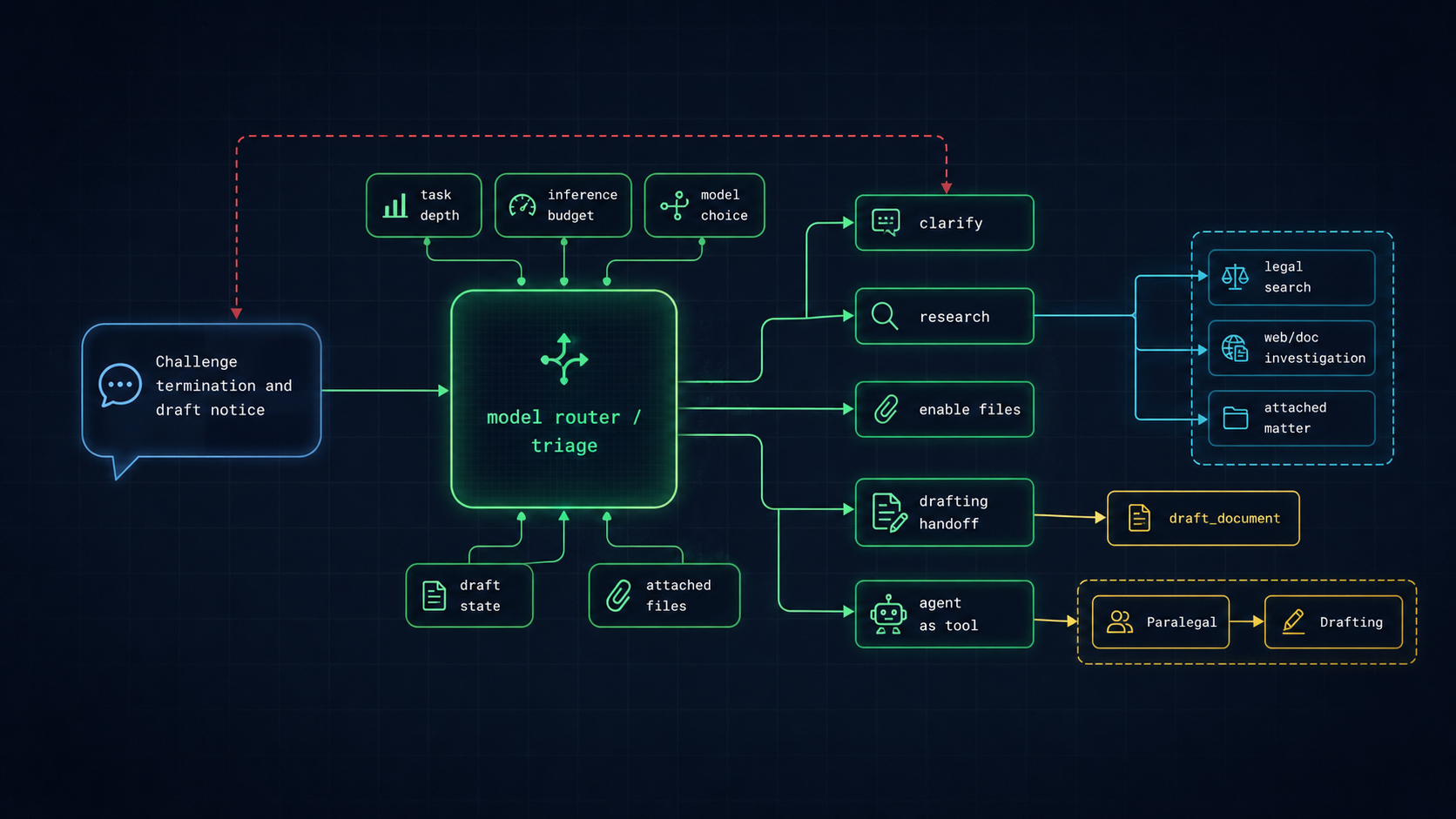
2. Hybrid, multi-engine search and parallel tools
Paralegal compiles a normal-language legal question into richer retrieval work. HyDE expands the semantic search space; structured queries constrain courts, dates, case numbers, statutes, and must-contain terms; vector, keyword, and summary search run together; results are reranked and grouped by source instead of dumped back as loose chunks.
The same run can call legal search, statute search, books, browser use, page fetch, web-document download and OCR, playbooks, attached Suit matter tools, and drafting tools. The visible trick is speed. The deeper trick is shaping retrieval for agents: enough detail to reason, enough compression to keep working, and enough provenance for lawyers to verify the answer later.
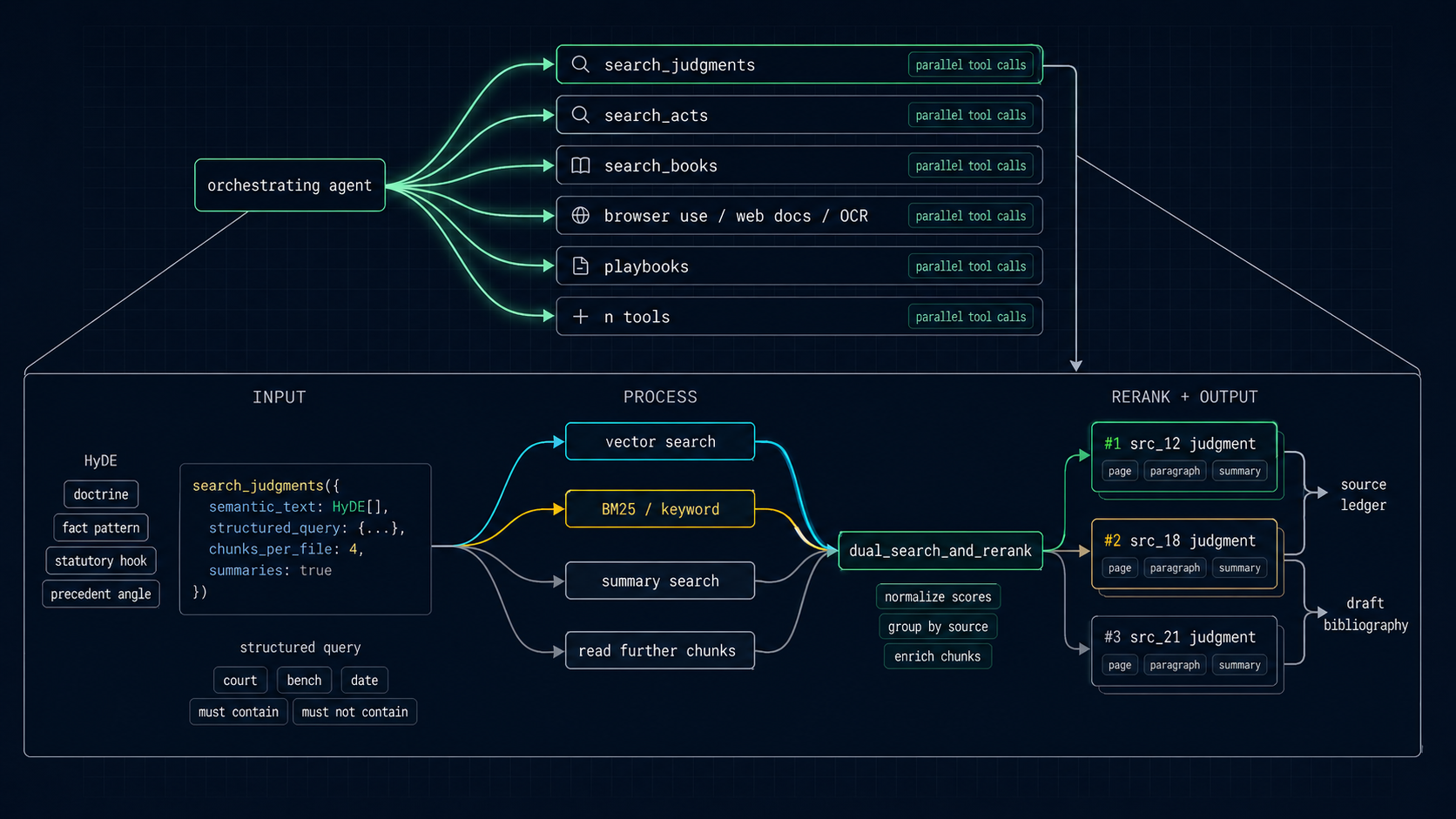
3. Persistent bibliography and jump to page
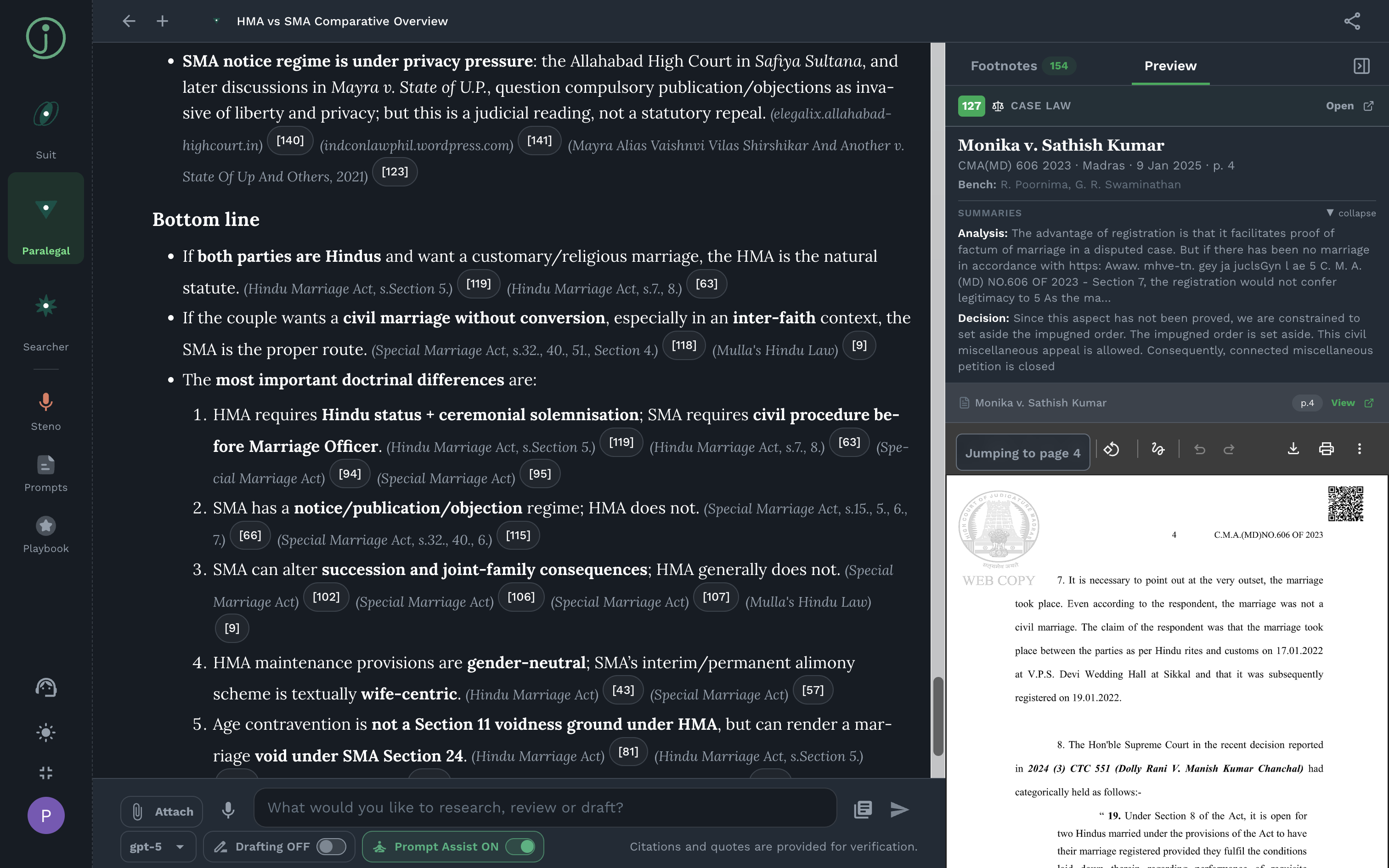
Source citations are first-class objects, not markdown footnotes guessed after the answer is written. Search, web fetches, Suit reads, and source reads flow into a persistent bibliography with page and paragraph pinpoints, preview text, and citation context.
This matters because a lawyer does not just need a good answer; they need to verify it. A footnote can open the exact source paragraph or page. Later, the same bibliography can be rendered into DOCX endnotes so that research provenance becomes part of the work product.
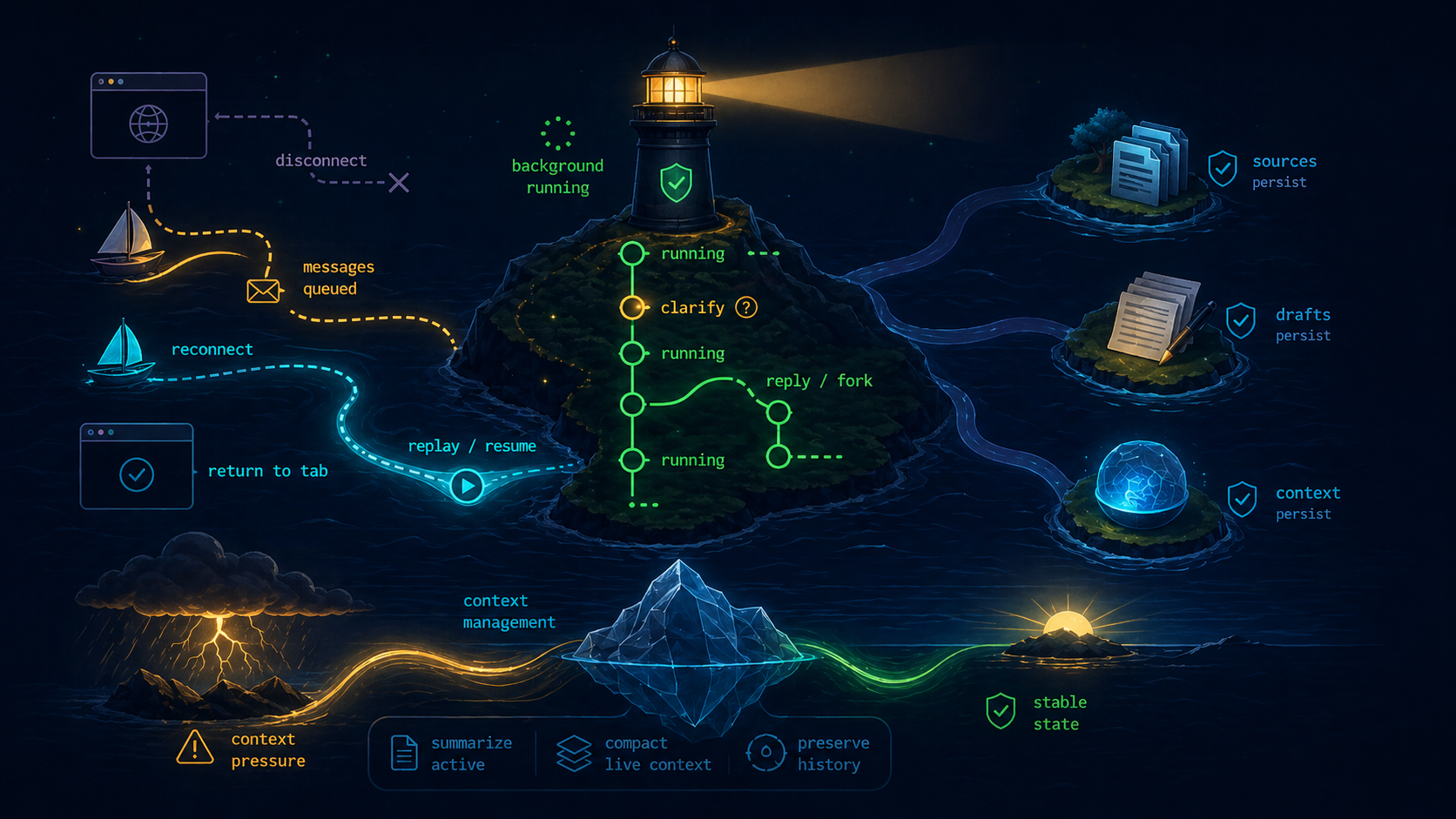
4. Long-running cloud agents
Long matters do not fit neatly inside one browser tab or one context window. Paralegal runs in the cloud, can keep working after a tab closes, replays progress when the user comes back, and treats disconnects as ordinary UI events rather than workflow failure.
The session separates active working context from durable matter history. The active thread can be summarized and compacted when the token budget is under pressure, while prior work, sources, drafts, and pending runs remain durable. Failed sends can be retried. Running tasks can be resumed. Older turns can be replied to as a branch.
This is one of those places where the boring engineering matters. The same lawyer-facing thread is simultaneously a chat, a run log, a source index, a draft workspace, a retry surface, and a forkable matter history.
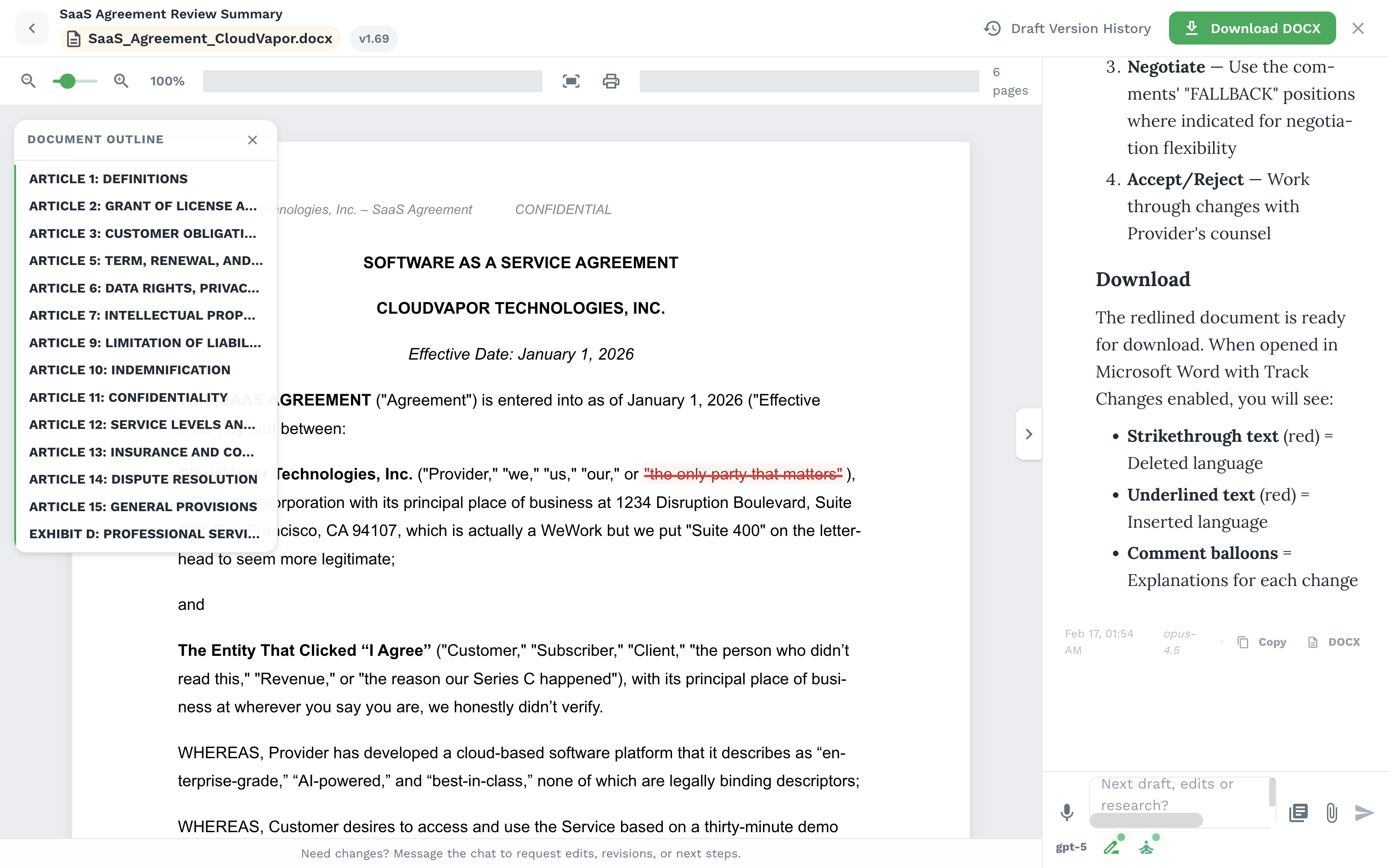
5. DOCX-native drafting and version control
Drafting is a separate runtime, not a text-generation endpoint. Paralegal can hand a structured legal brief into a drafting agent: facts, issues, clauses, authorities, bibliography, attached matter context, and instructions. The drafting system then works on an actual DOCX workspace.
The tool surface includes paragraph inspection and edits, replacements, deletions, tables, headers, footers, comments, redlines, footnotes, citation rendering, and PDF preview. When high-level Word abstractions are not enough, the system can drop to Word's real document structure. Version control tracks major/minor draft versions, content hashes, changelogs, diffs, and revert points.
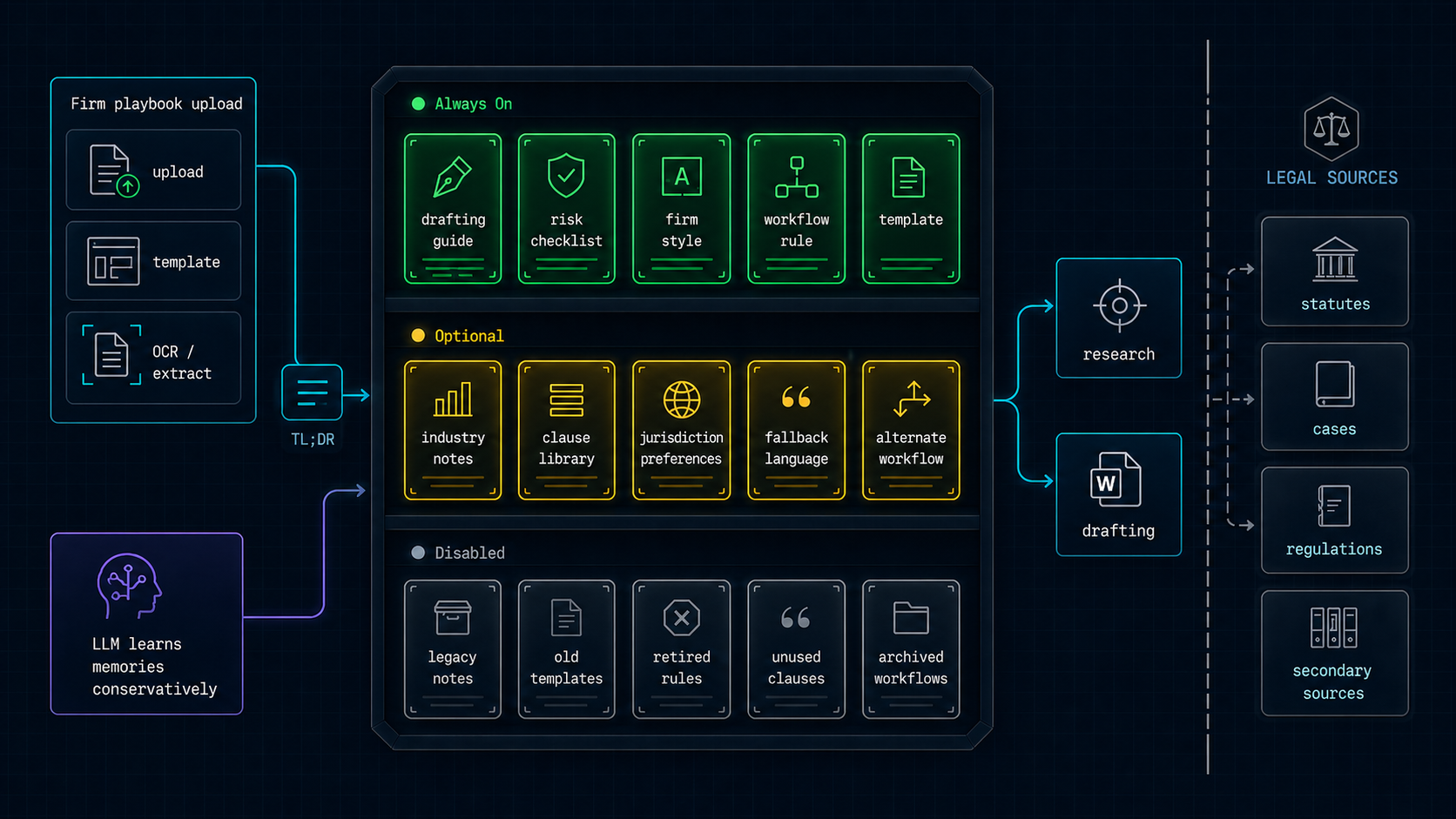
6. Org playbooks and global memory
Playbooks are practice memory, not legal sources. A firm can seed house style, drafting guides, checklists, templates, and workflow rules. Entries can be always-on, optional, or disabled. Always-on memories are injected into the agent context; optional memories are retrieved only when relevant through the playbook search tool.
The system can also infer reusable preferences conservatively, with guardrails, deduplication, and filters against case-specific facts. Uploaded playbook files are parsed, OCRed where needed, summarized into a TL;DR, indexed, and made available to future research and drafting.
7. Model agnostic by design
The agent runtime is model agnostic. The point is not to bet the legal workflow on one provider. Different steps can use different models: fast routing, deep research, long-context summarization, careful drafting, or user-supplied keys. The legal memory, bibliography, draft state, and playbooks remain jhana-owned product infrastructure around whichever model is best for the task.
That is the technical shape of Paralegal: model choice outside, legal execution inside. The differentiated work is not merely the agent harness. It is the execution substrate around it: task routing, hybrid legal retrieval, persistent source control, resilient sessions, DOCX-native editing, versioned work product, and practice memory.
See also: Model-agnostic future and Tech stack 2026.
Discussion